Nginx负载均衡系统引发的问题和分析过程
过程描述
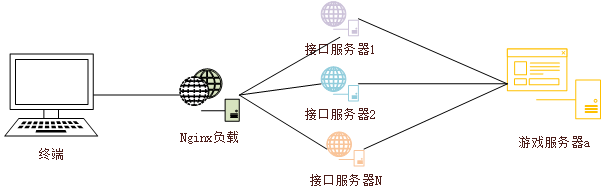
- 先讲解我司网络模型,最终用户请求接口服务器中间有一Nginx来担当负载系统。负载策略,当所有服务器正常时,n台接口服务器轮训调用。当负载系统请求接口1异常时[比如502Getway Timeou],Nginx会继续轮训第二台接口服务器,如果n-1台全部报错会一直调用到n。
- 我司实际业务,终端请求接口服务器,接口服务器调用游戏服务器为玩家发放虚拟物品。Nginx与接口服务器n均在同一机房,游戏服务器在异地。
- 有一个阳光明媚的下午,巡服程序发现游戏内玩家有大家重复道具。查询接口服务器记录的DB日志,所有异常账号均只有一条记录。查询终端上传日志均只调用一次,无恶意多次并发点击。但游戏服务器内接口日志显示调用多次。此时无解状态。
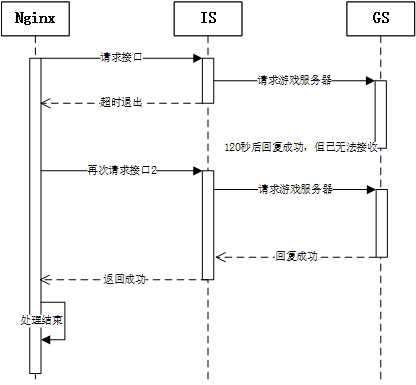
- 后细心观察接口服务器上WEB服务器的访问日志发现同一账号n台服务器全部请求过一次,但从1到n均报超时错误。
- 后来做网络请求测试发现从接口服务器到游戏服务器IDC机房网络异常PING值在90秒以上。并查看程序代码,业务逻辑为接口服务器优先请求游戏服务器发送物品,当到达90秒超时时间后退出程序不记录成功日志,但此时该请求实际已经到达游戏服务器并执行发放操作。当Nginx接收到接口服务器1异常后会轮寻接口服务器2,故障重复直到某台机器时网络正常轮寻成功后记录一条发放日志,并结束NGINX轮寻操作。此时玩家在游戏服务器内就已拿到多份奖励。
后续解决方案
- 考虑在发放物品接口上增加订单号。
- 改变Nginx的负载机制。
- 增加网络异常时的报警
BTW:以上描述部分情节为虚构,比如架构图有抽象部分。
如果觉得文章内容比较实用,期望获得更新通知,请关注公众号:
