使用人脸识别的出勤打卡程序

6月初北京的疫情响应已经降到了三级,没想到中旬时疫情又卷土重来,每天都有10~30个确诊病例的新增,按专家的说法秋冬季还会更严重。公司之前一直使用基于指纹的上下班签到机制,疫情期间为了减少人员接触开始改用人脸打卡。当时以为只是应急用一下,疫情有一两个月就结束了,使用的第三方的人脸打卡程序。但目前已经过去5个月了,疫情还没有结束的迹象。继续使用第三方的打卡程序:一是数据不安全人脸&位置数据全被第三方收集走了,另一方面第三方没有提供接口无法和公司现有的考勤程序进行数据对接。公司希望实现自己的基于人脸打卡程序,这个重任当然就落到了我们开发部上,虽然没经验但咱们做为一个涉身职场多年的老将不能说不行啊。
我们先看下最终的出勤打卡效果吧:
方案选型
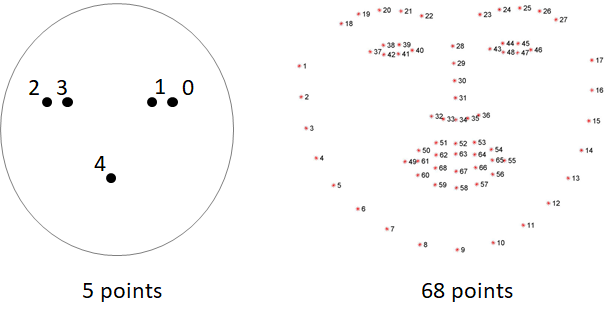
目前是通过平面照片来识别的,先扫面照片上的人脸,然后在查找到的人脸上打上若干特征点(主要是5点和68点),之后把特点转化为数字向量。如果两个基础数据和本次测试数据的向量差小于一个阈值我们可以认为这是同一张人脸。
我们最终选择了dlib这个人脸识别类库,他有C++和Python版本的接口,并支持cuda硬件加速。为了便于快速开发我们肯定会选择Python版本。
先说一下开发环境的准备,dlib可以通过pip的方式来安装,建议使用python3.6以上版本。dlib需要依赖cmake进行编译,如果是mac平台可以通过 brew install cmake 来进行安装。Windows平台需要去CMake官网下载安装包来进行安装。之后我们再使用pip install dlib来安装依赖库。
前面提到了特征点可以用5点或68点了,为了提高识别准确度我们使用68点。dlib在做人脸特征点检测时首先需要一个训练好的68个特征点的学习文件shape_predictor_68_face_landmarks.dat以及做向量转化的人脸识别模型dlib_face_recognition_resnet_model_v1文件。
接下来我们打开你喜欢用的python IDE来准备测试代码的编写。
# -*- coding: UTF-8 -*-
import dlib
import numpy
# 上一步准备好的两个文件
predictor_path = './shape_predictor_68_face_landmarks.dat'
face_rec_model_path = './dlib_face_recognition_resnet_model_v1.dat'
# 准备两个待比较照片
base_pic = './base.jpg'
test_pic = './test.jpg'
# 加载 文件
detector = dlib.get_frontal_face_detector()
sp = dlib.shape_predictor(predictor_path)
facerec = dlib.face_recognition_model_v1(face_rec_model_path)
# 加载基础人脸照片
face_img = dlib.load_rgb_image(base_pic)
# 识别照片中是否有人脸出现
face_dets = detector(face_img, 1)
# 当前不做错误检查,建设基础照片人只有一个需要识别的人脸。识别人脸的68个特征点
shape = sp(face_img, face_dets[0])
# 转化为128维的向量
face_descriptor = facerec.compute_face_descriptor(face_img, shape)
# 转化为numpy数组方便下一步的比较
base_num_array = numpy.array(face_descriptor)
# 以上已经完成基础照片的加载,再两样步骤加载待测试照片
face_img = dlib.load_rgb_image(test_pic)
face_dets = detector(face_img, 1)
shape = sp(face_img, face_dets[0])
face_descriptor = facerec.compute_face_descriptor(face_img, shape)
test_num_array = numpy.array(face_descriptor)
# 进行相似度比较
dist = numpy.linalg.norm(base_num_array - test_num_array)
print('两个人脸相似度为 %f' % dist)
把以上代码保存起来比如我们存为main.py,就可以进行测试了
[root@localhost test]# python3 main.py
两个人脸相似度为 0.324054
测试的结果为一个0~1之间的浮点数,越接近0证明两个人脸越相似。经我们测试这个数设置在0.4是一个比较理想的值。小于等于0.4即可认为是同一个人
性能问题
我们使用单线程进行测试,发现这程序占用CPU好严重,这要是实际应用打卡多人同时打卡的情况CPU不得被使用爆炸了。
经过查询资料以及打点,发现主要可优化的有以下几个部分,首先那两个训练文件巨大肯定要修改为优先程序启动后只加载一次。另外最占CPU时间的就是compute_face_descriptor方法。对于基础照片可以把numpy后的向量数组进行存盘,这时每次再做比较时只对一张照片进行向量化即可。
另外下dlib在使用英伟达家显卡时可以使用GPU进行计算,可以大幅降低CPU的负载。推荐使用类Linux平台来安装cuda驱动。这里我使用centos7为例子进行安装。
# 首先安装一些依赖要使用的软件
[root@faceid ~]# yum install -y wget pciutils gcc-c++ cmake gcc kernel-devel kernel-headers python3 python3-devel freeglut-devel libX11-devel libXi-devel libXmu-devel make mesa-libGLU-devel libXrender
# 接下来我们确认下机器内的显卡是否为英伟达的
[root@faceid ~]# lspci | grep -i vga
01:00.0 VGA compatible controller: NVIDIA Corporation GP107 [GeForce GTX 1050 Ti] (rev a1)
07:00.0 VGA compatible controller: NVIDIA Corporation GP107 [GeForce GTX 1050 Ti] (rev a1)
# 屏蔽下系统内的nouveau驱动,启动nvidiafb的驱动
[root@faceid ~]# vi /lib/modprobe.d/dist-blacklist.conf
# 注释掉blacklist nvidiafb并在后面追加两行
#blacklist nvidiafb
blacklist nouveau
options nouveau modeset=0
# 重新生成内核并重启
[root@faceid ~]# mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
[root@faceid ~]# dracut /boot/initramfs-$(uname -r).img $(uname -r)
[root@faceid ~]# reboot
# 测试下驱动是否屏蔽成功,如果无输出代表屏蔽成功
[root@faceid ~]# dmesg|grep nouveau
# 下载CUDA Toolkit,目前最新版本已经到11了,但我 这里测试对python兼容性不好,推荐使用10.x版本。
# 可以前往这里按你的系统进行下载,对于类Linux系统推荐使用.run的方式下载完整文件
[root@faceid ~]# wget https://developer.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.168_418.67_linux.run
# 增加可执行权限
[root@faceid ~]# chmod +x cuda_10.1.168_418.67_linux.run
# 安装过程中会询问是否要安装nvidia驱动,同意即可
[root@faceid ~]# ./cuda_10.1.168_418.67_linux.run
# 按屏幕最后的提示为你的系统增加相应的环境变量。
[root@faceid ~]# vim ~/.bashrc
# 文件结尾增加
export PATH=/usr/local/cuda-10.1/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
# 全部安装好后我们使用nvidia-smi查看来是否安装正常。
[root@faceid ~]# nvidia-smi
Mon Jun 29 10:40:44 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.67 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 105... Off | 00000000:01:00.0 Off | N/A |
| 40% 34C P8 N/A / 75W | 288MiB / 4039MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 105... Off | 00000000:07:00.0 Off | N/A |
| 40% 31C P8 N/A / 75W | 288MiB / 4040MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 12810 C python3 278MiB |
| 1 12907 C python3 278MiB |
+-----------------------------------------------------------------------------+
# 如上输出代表已经正常识别到我们的显卡
# 安装cuDNN。前往 https://developer.nvidia.com/cudnn 根据你的CUDA版本下载对应的cuDNN并安装
[root@faceid ~]# tar -xzvf cudnn-10.2-linux-x64-v7.6.5.32.tgz
[root@faceid ~]# cp cuda/include/cudnn.h /usr/local/cuda/include
[root@faceid ~]# cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
[root@faceid ~]# chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
# 如果你和我一样已经安装过dlib了,需要卸载再重新安装dlib才会支持基于cuda的dlib
[root@faceid ~]# pip uninstall dlib
[root@faceid ~]# pip install dlib
# 安装过程中看到如下提示,代码已经启动cuda硬件支持
-- Looking for cuDNN install...
-- Found cuDNN: /usr/local/cuda/lib64/libcudnn.so
-- Enabling CUDA support for dlib. DLIB WILL USE CUDA
以上都修改完后我们再重新测试下我们的程序,发现性能提升很多。不再占用CPU时间,而且每次处理都可以控制在毫秒级别。
转化为WEB项目
接下为就考虑如何让用户进行打卡了。第一个考虑到的是做手机上的APP,但想到要兼容iOS+Android也是个不小的成本。第二个考虑到的就是做小程序,做成微信的小程序还可以关联到企业微信内,直接就能读取用户在企业内的真实姓名很是方便。那么我们的服务端就要考虑转化为WEB项目。参考了几个python的web框架后发现tornado比较轻量化,更适合我们这种只有接口的项目。
先看下简化版本的流程图,当然如果你想用到实际环境中肯定还要考虑几点算是上班和下班,要给用户不同的提示。以及是否要限制打卡的GPS坐标范围,甚至是连接的网络之类的。
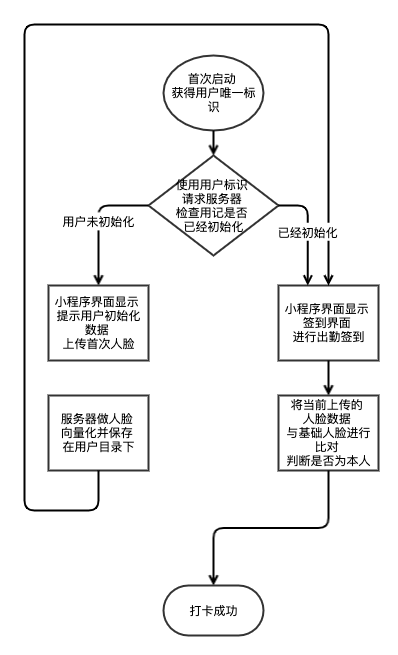
具体的这块代码比较多不再做更多讲解,我做好一个DEMO放到了github里,大家可以去参考学习face-clockin项目
如何以Docker方式来运行
如果你和我们一样需要使用k8s方式来管理部署服务器,可以还要面临打包成docker镜像的方式来运行。打成docker方式肯定好处多多,再新增加机器只需要安装cuda驱动即可,但dlib、odbc驱动之类的,只要容器里有即可正常使用。
如果想顺利的运行基于cuda的docker需要docker的版本至少是19.03以上。并安装相应系统的NVIDIA Container Toolkit我们以centos为例子看下安装的过程
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
sudo yum install -y nvidia-container-toolkit
sudo systemctl restart docker
docker的基础名字为nvidia/cuda具体要使用的版本看你的需求情况,我这里还是以centos7为例子进行运行。
# 测试Docker下cuda支持情况
[root@faceid ~]# docker run --rm --gpus all nvidia/cuda:10.1-cudnn7-devel-centos7 nvidia-smi
Tue Jun 30 02:41:20 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.67 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 105... Off | 00000000:01:00.0 Off | N/A |
| 40% 32C P8 N/A / 75W | 288MiB / 4039MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 105... Off | 00000000:07:00.0 Off | N/A |
| 40% 29C P8 N/A / 75W | 288MiB / 4040MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
以为上基础,我们来看看咱们项目的Dockerfile应该如何写
FROM nvidia/cuda:10.1-cudnn7-devel-centos7
MAINTAINER GUOHAI.ORG
WORKDIR /opt
RUN yum -y install gcc-c++ cmake gcc kernel-devel kernel-headers git python3 python3-devel freeglut-devel libX11-devel libXi-devel libXmu-devel make mesa-libGLU-devel gcc-c++ libXrender && \
git clone https://github.com/davisking/dlib.git && \
cd dlib && python3 setup.py install
RUN yum -y install unixODBC unixODBC-devel && \
curl -O https://cdn.mysql.com//Downloads/Connector-ODBC/8.0/mysql-connector-odbc-8.0.20-1.el7.x86_64.rpm && \
rpm -ivh mysql-connector-odbc-8.0.20-1.el7.x86_64.rpm && \
myodbc-installer -d -l
WORKDIR /opt/webserver
COPY requirements.txt ./
RUN pip3 install --no-cache-dir -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
COPY *.py ./
COPY dlib_dat/*.dat ./dlib_dat/
COPY conf/* ./conf/
RUN mkdir /opt/webserver/uploads
CMD ["python3", "/opt/webserver/main.py"]
运行的时候晃得要加上–gpus 的参数。下面举例的镜像名是我上传的打卡程序的镜像,可以直接使用
# 使用所有显卡
[root@faceid ~]# docker run --rm --gpus all gcontainer/face-clockin:0.1
# 仅使用第一块显卡
[root@faceid ~]# docker run --rm --gpus device=0 gcontainer/face-clockin:0.1
人脸识别功能的扩展
通过上面的教程,我们可以进行一下扩展利用人脸识别的技术。对我们硬盘里存储的多年照片进行下人脸归类。哪些照片有你出现,哪些照片有你的朋友A出现。现在不用上传到云相册就能实现这一整套的归类管理,避免了隐私的泄漏。只能感叹一下现在各种新技术的应用成本越来越低了。
如果觉得文章内容比较实用,期望获得更新通知,请关注公众号:
